The Art of Writing Deployment Pipelines
Written on

This post comes late after my EuroPython 2019 talk on “Modern Continuous Delivery” in Basel. But there is no need to worry: Advice on writing software that outlasts hypes on modern computing has no hurry to appear on stage.
What a great time!
Deployment automation, cloud platforms, containerization, short iterations to develop and release software—we’ve progressed a lot. And finally it’s official: Kubernetes and OpenShift are the established platforms to help us do scaling and zero downtime deployments with just a few hundred lines of YAML. It’s a great time.
Can we finally put all our eggs into one basket? Identify the cloud platform that fits our needs, and jump on it? That could well backfire: Vendor lock-in is the new waterfall, it slows you down. In future you’ll want to jump over to the next better platform, in a matter of minutes. Not months.
So, how do we do that? What’s the right approach?

The definition of Continuous Delivery
What does modern software development look like?
A modern software development project does:
- Immutable infrastructure (“containerization”)
- Container orchestration (e.g. Kubernetes, Docker Swarm)
- Version control and automation (CI/CD, “pipelines”)
- Cloud-native applications (resilient apps that scale)
Nothing new. You’ve heard this before.
Vendor lock-in is the new waterfall
Software development has become complex. So complex that there are numerous services popping up almost daily that help us getting things done. Most notably, these are application delivery platforms nowadays (Amazon AWS, Microsoft Azure, Google Cloud — just to name a few). When we use offerings across several such providers, which is becoming increasingly popular, we speak of multi-cloud dependencies.

Is there a difference between a choice and a lock-in?
While all offerings are choices they typically entail a lock-in, because we don’t have standards and tooling yet that allow us to effortlessly switch from one solution provider to another. And when there are reasons to make a switch, lock-ins make it inherently difficult to move fast. This is a problem.
What can we do about vendor lock-in?
Software development is not about “using <technology>” or “using <platform>”. As engineers we must think in terms of “problem to solve” (requirements) and applying proper development practices (engineering). If we rely on platforms to solve problems for us we’re doing it wrong. Engineers must learn to follow principles of good software design, to write and maintain “clean code”.

Responsibility layers
One of those principles you learn as an engineer is to maintain boundaries between systems. In a modern software development project you’ll see four of such “layers of responsibility” that define boundaries:
- Application
- Development
- Deployment
- Automation
Think in terms of technologies and tools, or services and environments you use in each to understand why we have those.
- The application layer is like how you did software development 15 years ago. It’s just concerned with getting things running locally. Add the 12factor app methodology and you get an application that is prepared for potential target environments.
- The development layer is concerned with supporting the development in the application layer. Developer tooling that gets the project running with a single command, a test infrastructure setup and QA tooling, which should also be easy to handle.
- The deployment layer reuses that part of the development layer that made the developer deploy the application locally, for development. It also houses configuration files used only in productive target environments and deployment configuration that describes the entire productive setup.
- The automation layer is only concerned about automating the steps you would otherwise perform manually to deploy your application.
Clean separation and interfaces
Now we have layers. What do we gain?
Note how the layers use an interface to talk to the next layer above. This allows us to address them separately. In other words,
- When you want to use a different CI service (e.g. switch from Bitbucket Pipelines to GitLab CI) you only refactor the implementation in the automation layer (i.e. the CI configuration).
- When you want to change your container orchestration (e.g. switch from
OpenShift to Kubernetes) you only refactor your implementation of the
deployment layer (e.g. use Kustomize instead of OpenShift templates
and Ingress instead of Routes, etc.). You may also have to change
some of the deployment tooling in the automation layer as a consequence
(e.g. use
kubectlinstead ofoc), but it’s all cleanly separated.
This is the power of separation of concerns.
Can you spot the DevOps responsibilities in the image of “layers”?
- “application development” = (artifacts and processes) of the Dev world
- “deployment automation” = (artifacts and processes) of the Ops world
It sounds like a contradiction, but good DevOps people keep all 2x2 concerns neatly separated.
—The modern world is a DevOps world
Also note that for this to work well you need to make your interfaces simple and stable.
- For development use a task runner to turn your common tasks into single
commands or simple one-liners (in JavaScript you may use
gulp, in Rubyrake, in Pythontox). - Don’t design for target environments in your application layer! Design with features in mind and only combine them to environment configurations in your deployment layer.
- Stick to standard procedures and established tooling (instead of proprietary or self-invented solutions) for the technologies you use. This is typically more stable as an interface, will save collaborators from learning how to work with your setup and make it unnecessary to add extensive instructions to the README.
The more you invest in this flexibility and clean separation the easier your task will be when the day comes to make a change.
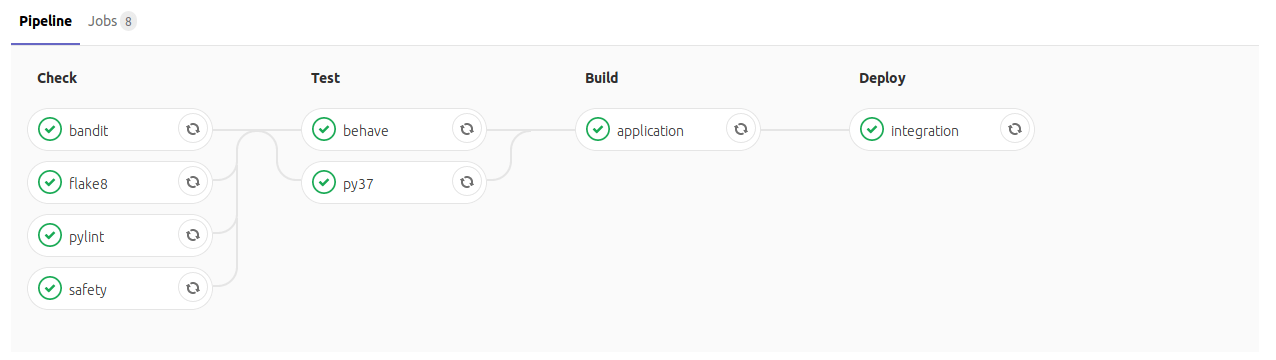
A delivery pipeline should be beautiful. Make sure you can tell a story!
Working code samples to your rescue
What is better than starting to investigate late and working on refactoring under time pressure? Knowing your possibilities and turning to working code samples when you need them!
That’s where the Painless Continuous Delivery Cookiecutter comes into play. It’s a project template generator covering many of the most popular combinations of public service offerings you may be working with. At VSHN AG we’re working on extending it—for your independence. Try it out, let us know if you find it useful, and contribute if you feel like!
For the start you may want to take a look at one of the generated setups on GitLab, the live demo for the EuroPython talk. Enjoy!
EuroPython 2019: Modern Continuous Delivery for Python Developers
Slides of this talk are available from SpeakerDeck.